
Table of contents
- Iterator vs aggregator: the short version
- First, understand bundles (everything depends on this)
- How the Iterator works, step by step
- How aggregators work, all four types
- The Source Module field, where everyone gets stuck
- Group by: one array per customer instead of one giant array
- What this costs you in operations
- Five mistakes that break the pattern
- Frequently asked questions
If you have spent any real time in Make, you have hit the wall: a module hands you an arraya list of line items, attachments, search results, rows, and the next thing you want to do has to happen once per item. Or the reverse: you have a stream of separate bundles and you need to fold them back into a single thing to send onward. That is the entire job of the Iterator and the Aggregator. Make’s own help pages describe each module in isolation, but they rarely show you the two as the matched pair they almost always are in practice. This guide does.
Iterator vs aggregator: the short version
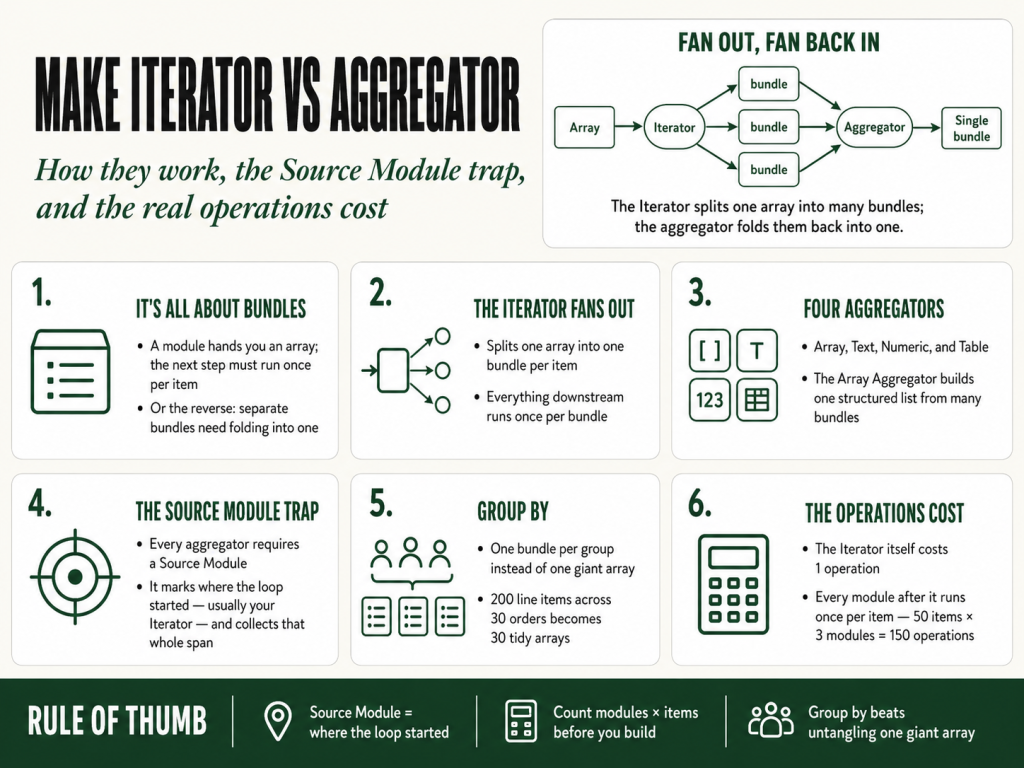
An Iterator takes one bundle containing an array and splits it into many bundles, one bundle per item in the array, so the modules after it run once for each item. An Aggregator does the opposite: it collects many incoming bundles and merges them back into a single bundle. You use the Iterator to fan out (process each item separately) and an aggregator to fan back in (combine the results). They are two halves of the same loop, and most of the trouble people have with either one comes from misunderstanding the thing they share: the bundle.
The mental model: Iterator = “explode this list into separate runs.” Aggregator = “gather those runs back into one result.” If you find yourself reaching for an Iterator, ask immediately whether you will need an aggregator downstream to put the pieces back together. Usually you will.
First, understand bundles (everything depends on this)
In Make, a bundle is a single packet of data moving through your scenario. When a trigger fetches one email, that email is one bundle. When a module produces several bundles, every module after it runs once per bundle, that is the rule that governs the whole platform, and it is the rule that makes iterators powerful and occasionally expensive.
An array is different. An array is a list that lives inside a single bundle. One email bundle might contain an array of three attachments. The attachments are not three bundles, they are one field, holding a list of three, inside one bundle. That distinction is the source of nearly every “why won’t this map?” question on the Make community forum. You cannot send an array straight into a module that expects to act on one item at a time. You have to convert the array (a list inside one bundle) into a series of bundles (one item each). That conversion is exactly what the Iterator does.
How the Iterator works, step by step
The Iterator is a built-in module. You find it under Flow Control in the module search (the same group as the Router and the Aggregator). It has exactly one meaningful setting: the Array field.
- Add the Iterator after the module that produces your array.
- Click the Array field and use the data picker to map the array you want to split, for example, the
attachments[]array from a “Watch emails” module. The square brackets in the picker tell you it is an array. - Save and run. The Iterator now outputs one bundle per item. If the array had five attachments, every module after the Iterator runs five times, once for each attachment, each as its own clean bundle.
Inside the Iterator’s output you also get a useful field called Bundle order position (and a total), so a downstream module can know it is handling “item 3 of 5.” That is handy for numbering files, building progress messages, or stopping after the first item.
The gotcha Make’s docs gloss over: many modules already iterate for you. A “Search rows” or “Watch records” module that returns 20 records emits 20 bundles on its own, you do not need an Iterator after it. The Iterator is only for when an array is trapped inside a single bundle (an attachments list, a line-items array in a webhook payload, a nested JSON array). Adding an Iterator where the module already produced separate bundles is the single most common beginner mistake, and it usually produces a confusing “array expected” error or simply does nothing.
How aggregators work, all four types
Where the Iterator fans out, aggregators fan back in. An aggregator sits downstream, receives all the separate bundles flowing into it, and emits a single bundle that combines them. Make ships four aggregators, and picking the right one saves you a pile of needless modules.
| Aggregator | What it produces | Reach for it when |
|---|---|---|
| Array Aggregator | One bundle containing an array of all the incoming bundles (you choose which fields to keep) | You need to pass a structured list onward, build a JSON payload, attach all files to one email, write many rows in a single API call. |
| Text Aggregator | One string, joining a value from each bundle with a separator you set | Building a report body, a comma-separated list, or a chunk of HTML from many rows. |
| Numeric Aggregator | One number: SUM, AVG, COUNT, MIN, or MAX across the bundles | Totaling an order, averaging scores, counting matches, math across a set. |
| Table Aggregator | One text table (rows and columns) from selected fields | A quick human-readable grid for an email or a Slack message. |
The Array Aggregator is the one you will use most, and the one most often paired with an Iterator. It is also the one with the setting that trips everyone up.
The Source Module field, where everyone gets stuck
Every aggregator has a required field called Source Module. This is the single most misunderstood setting in Make, and the Make docs explain it in one terse line. Here is what it actually does.
The Source Module tells the aggregator where the loop startedwhich earlier module’s bundles it should wait for and collect. Make watches everything between the Source Module and the aggregator, and bundles up that whole span into one output. In the standard pattern, your Source Module is the Iterator: you are telling the aggregator, “gather everything produced for each item the Iterator emitted, then give me one bundle back.”
Get this wrong and the symptoms are confusing rather than loud. Point the Source Module too far downstream and you aggregate fewer bundles than you expected. Point it at the wrong branch and the aggregator emits the moment each bundle arrives instead of waiting for the full set, so you get many small “arrays” of one item each rather than one complete array. If your Array Aggregator is producing one output per item instead of one combined output, the Source Module is almost always the cause.
Rule of thumb: the Source Module is the module that first created the multiple bundles you want to collapse. If an Iterator created them, the Iterator is your Source Module. If a “Search rows” module created them, that search is your Source Module, and you do not need an Iterator at all.
Group by: one array per customer instead of one giant array
The Array Aggregator has an optional Group by field that quietly solves a problem people otherwise hack around with extra scenarios. By default the aggregator dumps every incoming bundle into one flat array. Set a Group by value, say, an order ID or a customer email, and instead of one giant array you get one bundle per groupeach carrying its own array.
Concrete example: you iterate over 200 line items that belong to 30 different orders. Without Group by you get a single array of 200 items and then have to untangle them. With Group by = Order IDthe aggregator emits 30 bundles, each containing only that order’s line items, already separated, ready to send 30 invoices. The grouping key shows up as its own field on each output bundle, so you can map it straight into the next step.
This pairs naturally with the Numeric Aggregator too: group by customer, sum the line totals, and you have a per-customer total in one pass instead of a nested loop.
What this costs you in operations
This is where the pattern can quietly drain your plan, and it is worth being precise. (Make renamed “operations” to credits in August 2025; for standard modules one operation still equals one credit, so the math below is unchanged, see our deeper breakdown in Make operations vs. credits.)
The Iterator module itself costs one operation. The expensive part is what comes after it, because every module downstream runs once per bundle. The arithmetic is simple and unforgiving:
Worked cost example. A trigger fetches one record (1 op). An Iterator splits its 50-item array (1 op). Each item then passes through three downstream modules (3 ops × 50 items = 150 ops). Total: 1 + 1 + 150 = 152 operations per single run. Double the array to 100 items and you are at 302. This is how a scenario that looked cheap in testing eats a month’s credits in a week.
The aggregator, by contrast, is cheap: it consumes one operation no matter how many bundles it collects, because it is a single module emitting a single bundle. That asymmetry is the lever. The way to control cost is not to avoid iterators, it is to do as little as possible inside the loop. Filter the array down before the Iterator, push as much work as you can into a single batch module (many APIs accept an array of records in one call, fed by an Array Aggregator), and never put a module inside the loop that could run once outside it. For the hard ceilings that govern all of this, see Make limits: the real ceilings.
Five mistakes that break the pattern
These are the failures that show up again and again, and the fix for each:
1. Adding an Iterator after a module that already emits bundles. If a search or “watch” module returned multiple bundles, they are already separate. An Iterator there is redundant and will error or misbehave. Only iterate arrays trapped inside one bundle.
2. Pointing the aggregator’s Source Module at the wrong module. The classic “why am I getting one array per item?” bug. Set the Source Module to the module that created the loop (usually the Iterator).
3. Mapping the whole array into a module instead of iterating it. Dropping an array directly into a field that expects a single value produces malformed output or an “array expected/collection expected” error. Iterate first, or use the right aggregator to reshape it.
4. Doing heavy work inside the loop. Every API call, every formatter, every filter inside the loop multiplies by the item count. Move anything that can run once outside the Iterator, and batch where the destination API allows it.
5. Forgetting the aggregator entirely. If the step after your loop needs the whole set, one email with all attachments, one API call with all rows, you must aggregate first. Sending un-aggregated bundles onward fires the final module once per item, which is usually not what you want and sometimes hits rate limits. When a downstream call does fail mid-loop, robust handling matters; see Make error handling.
Frequently asked questions
Do I always need an aggregator after an Iterator? No. If each item should be processed independently and nothing downstream needs the items combined, saving each attachment to its own file, for instance, you can end the loop without aggregating. You only need an aggregator when a later step requires the whole set as one thing.
Why is my Array Aggregator outputting one bundle per item instead of one combined array? Almost always the Source Module is set incorrectly. It should point to the module that started the loop (typically the Iterator). If it points somewhere downstream or to the wrong branch, the aggregator emits per bundle instead of waiting for the full set.
How much does an Iterator cost in operations? The Iterator itself is one operation. The cost comes from the modules after it, each of which runs once per item. Fifty items through three modules is 150 operations for that segment alone, so filter before you iterate and batch where you can.
What is the difference between the Array Aggregator and the Text Aggregator? The Array Aggregator outputs a structured array (a list of items you can map field by field downstream). The Text Aggregator outputs a single joined string. Use Array when the next module needs structured data; use Text when you are building a report, a message, or a delimited list.
Can I aggregate without ever using an Iterator? Yes. Any module that produces multiple bundles, a search, a “watch” trigger, a Router branch, can be the Source Module for an aggregator. The Iterator is only needed when your multiple items are locked inside a single bundle as an array.
What does Group by actually do? It splits the aggregated output into separate bundles by a key you choose (order ID, customer, category). Instead of one array containing everything, you get one array per group, with the grouping key attached to each output bundle.
Get the Builder’s Companion Kit (free). The iterator-and-aggregator pattern is one of a handful of building blocks that show up in almost every real Make scenario. We packaged the rest, labeled reference cards, six importable starter blueprints, and an operations cost estimator, into the Builder’s Companion Kit. Grab it free at Get the kit →.
You will need a Make account to import the blueprints. If you do not have one yet, create a free Make account herethe free plan is enough to run everything in the Kit while you learn the platform.
More Make guides
Free · Make Operator Toolkit
Running scenarios in Make?
Get the free operator toolkit — production checklists and the fixes that keep scenarios alive under real traffic, plus a note when this guide changes.
Get the free toolkit →